在人工智能引领的时代浪潮中,算力已成为技术进步与创新的核心驱动力。面对当下AI算力需求的飙升、高端AI芯片供应受限的挑战,加之OpenAI带来的技术封锁,唯有坚定不移的发展自主可控的国产技术方案,持续壮大国产智算集群规模,才能一路突破围追堵截,进一步促进国产大模型产业生态繁荣。
作为中立、安全的云计算服务厂商,优刻得持续发力人工智能智算领域,与国内主流AI芯片厂商深度合作,共同搭建的「国产千卡智算集群」现已上线商用。国内顶尖的AI创新型研发机构北京智源人工智能研究院(下称:智源研究院)成为首批用户,标志着优刻得自主可控的国产GPGPU算力底座有能力支撑大模型研发与验证,双方在国产AI智算领域的合作正式开启。
国产千卡智算集群,支持千亿参数大模型训推
优刻得国产智算集群基于国产通用GPU(GPGPU)所建设,能够快速构建大规模分布式训练环境,可支持超千卡规模、千亿参数级别的大模型训练和推理任务,旨在突破算力瓶颈,加速AI算力的国产化进程。
国产千卡智算集群采用软硬件一体化的架构设计,提供低延迟、高吞吐、高可用的IB组网环境,支持GDR技术,使得集群在算力获取、数据传输和算力调度等方面具有极高的效率。经过精心适配和调优,优刻得国产智算集群现已在上海青浦智算中心全面部署,智源研究院正基于国产算力更高效地完成大模型的训推工作。
●突破算力瓶颈,技术自主可控
基于国内知名AI芯片厂商所自研的高性能GPU IP,优刻得国产智算集群具有强大的多精度混合算力、64G大容量高带宽显存以及先进的多卡互联技术,特别适合千亿参数AI大模型的训练和推理,且增强了技术的自主性。在计算精度、稳定性、易用性和算力利用率等方面,优刻得国产智算集群均表现出优异特性,助力智源研究院在千亿MoE大模型训练方面取得了显著成效。
智源研究院成立于2018年,其推出的「智源悟道大模型」,是中国首个大模型,为中国人工智能技术发展奠定了深远的研究基础。在2024北京智源大会上,智源研究院公布了大模型全家桶。当前,智源研究院正在优刻得国产智算集群上持续进行更为复杂的模型结构设计和参数调整,以不断提升大模型迭代速度和自研水平。

基于全自研的虚拟机技术和显卡高效直通技术,优刻得国产智算集群还实现了多用户机器隔离和快速处理GPU故障等功能,确保GPU算力的高效利用。目前,优刻得国产GPU算力底座不仅提供海量算力支持,有效支撑了智源研究院进行国内领先的大模型研发,也进一步论证了国产芯片在收敛性上对于千亿模型的训练的有效性,性能比肩国际一流的同类GPU产品。
●支持异构混训,模型研发更高效
随着多元异构算力成为新的发展趋势,当前智源团队也正致力于研究在多芯片上实现大模型稳定高效训练与推理的并行框架,助力国产算力规模应用和大模型成果转化。智源联合优刻得、国产芯片厂商,共同探索“混训集群”的构建,并证实了优刻得国产智算集群与英伟达主流计算平台混合组网、异构混训的可行性。

得益于国产AI算力加持,智源研究院基于优刻得国产智算集群完成了多元异构大模型训练平台的搭建,并在实训中实现了长时间的稳定训练不中断。联合测试表明,智源研究院推出的开源大模型并行训练框架FlagScale可以支持国产芯片做为算力支撑:FlagScale支持基于国产算力的8x16B千亿参数MoE语言大模型1024卡40天以上的稳定训练,全面帮助用户实现高效稳定的集群管理、资源优化、大模型研发。
●生态兼容,灵活支撑业务发展
优刻得国产智算集群全面兼容CUDA等主流GPU生态软件栈,这意味着企业能够将CUDA应用零成本迁移到国产智算平台,实现快速适配。集群还提供了完善高效的软件栈工具,集成多种主流的深度学习编程框架,通过测试验证,确保了对行业领先人工智能模型的高效支持,做到开箱即用,用户可快速投入模型的开发和部署,加速了其在人工智能领域的布局和发展。
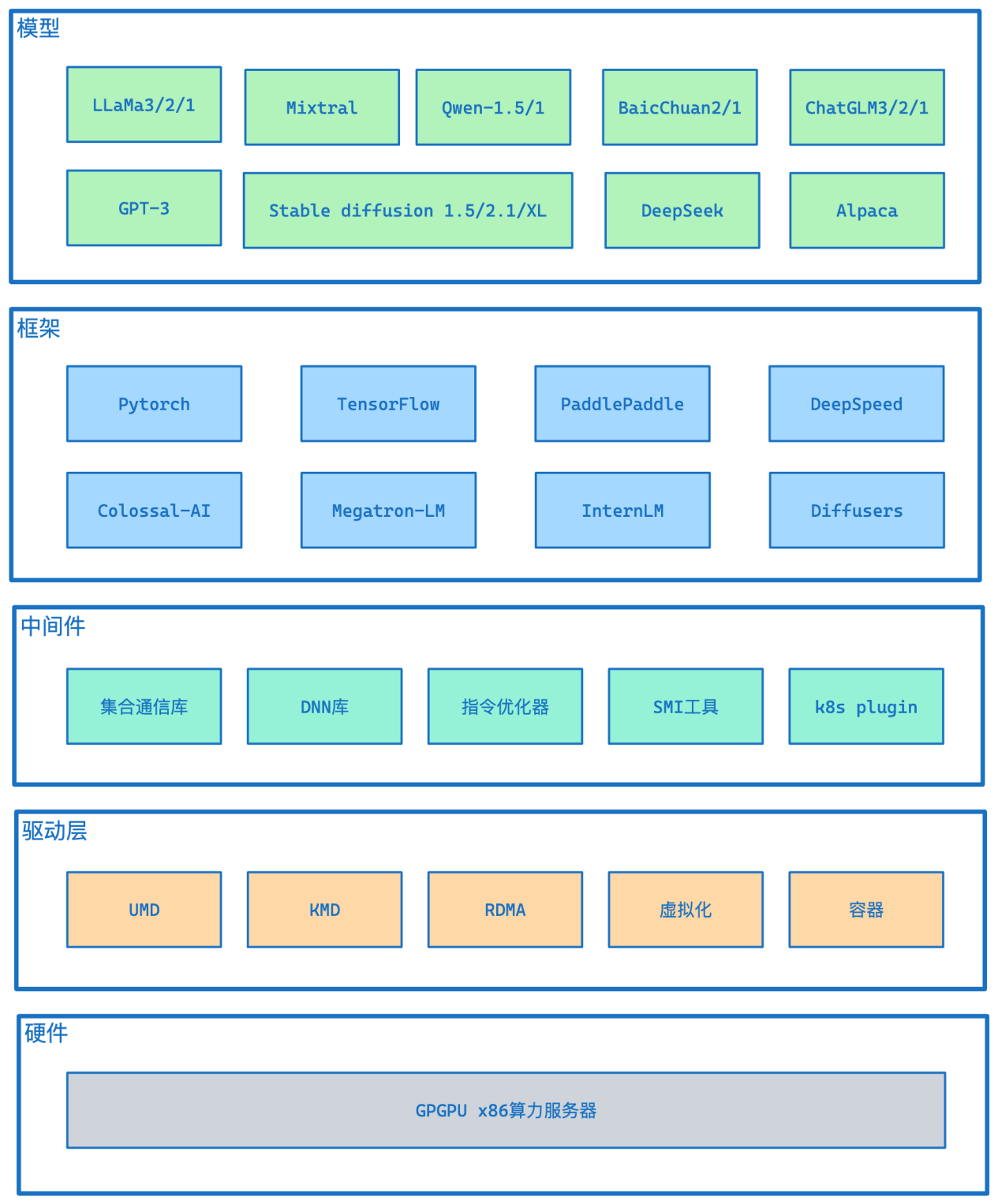
其中,FlagGemm是智源研究院主导开发的一套高性能大模型算子库,技术路线上是基于OpenAI Triton编译器,具有高性能、覆盖广、轻量级的多个优势。优刻得国产智算集群通过适配和支持FlagGemm算子库,实现了强大的生态兼容性和灵活的业务支撑能力。
随着OpenAI决定终止对中国大陆的AI服务,国内对于建设自主可控智算平台的需求愈发迫切。优刻得致力于构建先进的AGI算力底座,携手合作伙伴共建大型国产智算集群,以高性能算力和全栈智算解决方案服务大模型训练和推理。随着更多用户的入驻和应用深入,优刻得国产千卡智算集群将不断推动我国科技创新与智算产业升级迈向新的高度。