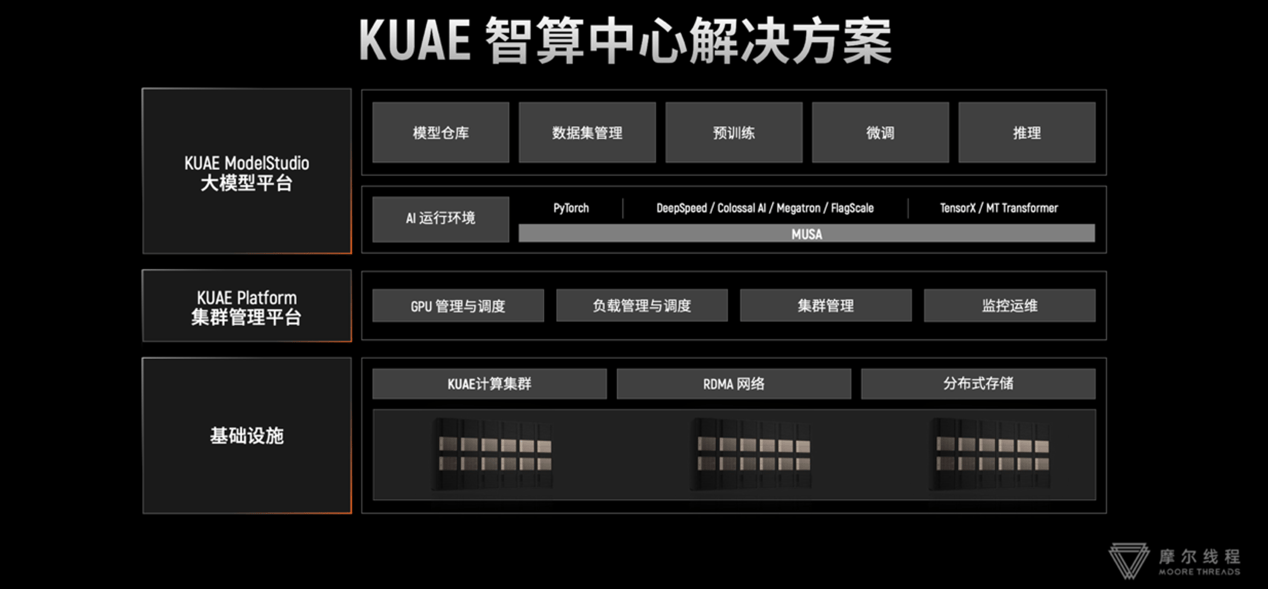
半年前,OpenAI CTO 米拉·穆拉蒂曾透露,公司正在研发一款 AI 图像识别工具,其准确度高达 99%,预计将很快公开发布。
最近,这款工具终于有了新的进展,OpenAI 于昨日宣布将向研究实验室和新闻机构开放申请,允许这些机构的研究人员并反馈使用体验。
具体来说,该工具能够检测任意一张图片是否由 OpenAI 旗下的图像生成器 DALL·E 3 生成。

据官方介绍,其识别成功率达到大约 98%,仅有 0.5% 非 AI 生成的图像会被错误地标记为 DALL·E 3 生成。并且,它还可以处理一些常见的修改,如压缩、裁剪和饱和度调整等。
但对于除 DALL·E 3 以外的图像生成工具,该工具的识别能力效果甚微,大概会有 5-10% 的误判率。

另外,OpenAI 还透露,他们正在「捣鼓」一种音频水印技术,可以在 AI 生成的声音中添加难以被篡改或移除的「水印」,使其在播放时能够被轻松识别。
面对 AI 生成内容日益泛滥的网络空间,OpenAI 官方表示将采用两种方法来应对这一挑战。
一是与其他组织合作,共同采用、开发和推广一个开放标准,这个标准能够帮助人们验证创建或编辑数字内容所使用的工具;二是开发新技术,这项技术专门用于帮助人们识别出由我们自己的工具所创建的内容。
为此,OpenAI 还加入了 C2PA(内容来源和真实性联盟)的指导委员会,并准备真实性标准的制定上大展拳脚。
公开资料显示,C2PA 是由 Adobe 和微软三年前牵头组成,其中 Meta、Google 等巨头也都是 C2PA 指导委员会的成员。

而 C2PA 标准就像是一种针对图像、视频、音频片段等文件的「制作信息标签」,它可以显示这些文件是在何时以及如何被制作或修改的,包括是否使用了 AI。
今年早些时候,OpenAI 就已经开始在由 DALL·E 3 创建和编辑的所有图片中添加 C2PA 元数据。此外,当视频生成模型 Sora 正式上线时,OpenAI 也会为其集成 C2PA 元数据。

实际上,OpenAI 在 AI 内容检测领域早已不是刚刚起跑的新手。
去年 2 月,在用户的强烈呼声中,OpenAI 推出了AI 文本检测器「AI Text Classifier」。
基于微调的 GPT 模型之上,该检测器能够推断一段文本由 ChatGPT 生成的可能性,实现了真正意义上的用 AI 检测 AI。
但这款工具检测成功率并不理想,即便在评估母语的英文文本时,大约只有 26% 的 AI 生成文本能被正确地归类为「可能是 AI 写的」。因此,推出几个月后,该工具就被 OpenAI 潦草下架。

除了内容检测领域,OpenAI 同期还在另一篇官方博客中宣布,他们正在开发一款名为媒体管理器的工具。
媒体管理器将允许创作者和内容所有者向 OpenAI 声明内容所有权,并决定他们的作品是否应该被纳入或排除在模型的研究和训练中。
未来,OpenAI 还计划为这个工具增添更多的选项和功能。他们的目标是到 2025 年推出这个工具,并希望它能成为 AI 行业的标准。

如今,在生成式 AI 汹涌而至之际,AI 生成的内容正以惊人的速度蔓延。
随手翻看的图片、日常浏览的文本,都可能完全出自 AI 之手,甚至为虚假信息和诈骗行为推波助澜。
与此同时,「始作俑者」 AI 巨头们在面对人类创作的内容时,却表现出了一种轻蔑的态度。比如 OpenAI 三天两头就深陷版权舆论漩涡。
早前即便是面对公众和媒体追问,管理层也往往用含糊其辞的话术来作出回应。
在法律总是稍微滞后的情况下,我们自然乐于看到诸如 OpenAI 等更多 AI 服务提供商开始勇于站出来,把守行业自律的前线。
OpenAI 不是第一个这样做的公司,也不会是最后一个这样做的公司。