8月11日-16日,第62届国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称 ACL)在泰国曼谷举行。
云天励飞大模型团队的论文《Generation Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding》被录用为ACL24的Findings长文。这是云天励飞大模型部分研究成果的阶段性展示。
ACL 年会是计算语言学和自然语言处理领域国际排名第一的顶级学术会议,由国际计算语言学协会组织,每年召开一次,在中国计算机学会(CCF)推荐会议列表中被列为 A 类会议。
云天励飞的入选论文提出了SPACE引擎—— 一种实现大模型推理无损加速的创新方案。在不同类型大模型测试的结果表明,使用SPACE引擎后,模型在HumanEval测试集上推理速度提升270%-400%,推理结果质量保持不变,可做到兼顾“算得快”和“算得准”。

云天励飞大模型团队的入选论文
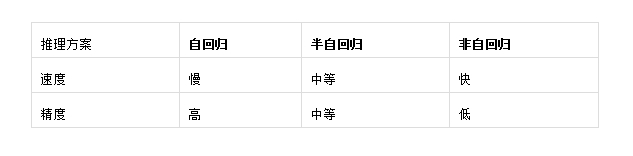
主流推理方案难以做到“既要又要”
SPACE是Smart Parallel Auto-Correct Decoding的简称,意为“智能并行自动纠错解码”。
这个推理方案有两大特点:一是采用半自回归推理模型,极大加快推理速度;二是在推理过程中加入验证手段,能够在提升推理速度的同时,保证推理精度。
“半自回归”是什么?为什么要加入验证的环节?在解释这些问题前,我们需要先了解一下当前大模型是如何“工作”的。
打开大语言模型的APP,我们在对话框输入“大模型是什么?”,大模型会逐字逐句地输出它的回答:“大模型是具有数千万参数的深度学习模型。”这个回答的过程看似很简单。但实际上,大模型在背后经历了多次“自回归”的循环。
首先,大模型会根据我们输入的内容,先预测输出的第一个字——“大”,然后把“大”字重新带回到输入端,基于“大”字预测下一个字应该输出什么。当然,这个“预测”并不是凭空“瞎猜”,而是模型会根据前期训练过程中见过的数据综合判断,选择概率最高的字,作为下一个输出字。
在这个案例中,第二个输出的字是“模”,输出了第二个字后,大模型会再次把“大模”这两个字带回到输入端,预测第三个生成的字。如此不断循环往复,直至完整的句子结束。
这个过程就是“自回归”。
目前,自回归是大模型推理采用的主流方案。无论是ChatGPT、开源的Llama,还是国内的一众大模型,主要都是采用自回归的推理方案。

自回归方案示意图
自回归方案的优势和弊端也十分明显。优势是能够确保生成的内容准确且有意义,而且上下文连贯。弊端是计算成本高、推理延时长。
为了克服这些问题,行业提出的解决方案是
“半自回归”是在“自回归”和“非自回归”之间的一种折中方案。上文提到,“自回归”是用已生成的词来预测下一个词;“非自回归”则是“自回归”的反面,一次性预测整个句子。“非自回归”方案能够提升推理效率,但是输出的精度却大打折扣。“半自回归”方案,则是综合考虑了“自回归”和“非自回归”的优缺点,平衡大模型推理对速度和精度的要求。
但是,采用“半自回归”方案又引发了新的问题——一是大部分大模型用不了,二是精度无法达到产业要求。主流大模型是按照自回归的推理模式打造的,如果要采用半自回归方案,则需要从头开始重新训练大模型。而训练一次大模型需要消耗大量的电力、算力、人力,几乎没有人会为了改变推理方案,把好不容易训练出来的大模型推倒重来。
另一个方案是“投机解码”。这一方案按照“草拟——验证”的流程工作,首先需要引入一个参数量相对较小的辅助模型,由小模型先“草拟”出候选答案,再由大模型去验证候选答案正确与否。得益于小模型相比大模型推理速度快,并且大模型能够同时对多个候选答案进行验证,这样的解码方式既能够保证输出结果的精度,同时也能够加快推理速度。
但是这个方案同样存在弊端。一是需要先做出十分“靠谱”的小模型,要能够又快又准地“草拟”出答案,而这本身就具有一定难度。二是两个模型之间要做到“书同文,车同轨,度同制”,在分词器、词表等方面做到高度一致,才能够保证验证结果。
SPACE推理引擎——小小改造、大大提速
既然几个方案都无法做到“既要又要”,有没有一种方案,能只保留它们的优点,规避他们的缺点呢?这就是云天励飞大模型团队提出的SPACE推理引擎。SPACE通过结合“半自回归监督微调”和“自动修正解码”两种方案,使得大模型能够在一次推理中生成多个结果,并且同步完成结果验证,保证生成结果的质量。同时,这套推理引擎适用于任何的大模型。通过模型的微调和优化,任何大模型采用该推理引擎时,不仅无需再训练额外的辅助模型,还能提高推理效率,充分利用GPU等并行计算资源,达到较高的算力利用率。

自回归方案(左)与SPACE方案(右)的区别
上文提到,多数大语言模型自带“自回归”的属性,无法直接套用“半自回归”的方案。对此,SPACE采用的是“半自回归监督微调”的方式,通过有监督的训练,模型学会在遇到特殊的[MASK]标识时提出一系列可能的候选字(如上图所示)。这使得模型在推理时能够进行类似“猜测”的操作,输出几个最可能正确的候选字,从而具备半自回归推理的能力。
简单来说,有了“半自回归监督微调”方案的加持,在推理时大模型自己就能够做出“猜测”,输出大概率是正确的多个字作为候选答案。
但是,就跟考试一样,草稿上可以列出大量的内容,但是填到考卷上的,必须得是正确答案。如何保证正确?这就需要对结果进行验证,而这就是“自动修正解码”要做的工作。
具体来说,在推理时,我们把大模型在上一步推理时自己生成的候选词也输入到模型中,让模型进行自我校验,自行判断这些候选答案是否正确。
判断的方式也很简单,如果模型生成的词与早先的候选答案相匹配,那就认为候选词是正确的。回顾下,在传统的自回归推理里面,如果一个词是正确的,那么这个词需要再重新输入到语言模型中去推理产生下一个词。
但是在SPACE这里却不需要。由于我们已经把候选词提前输入到模型中,并且这个候选词被验证是正确的,所以这时候我们就可以直接从正确的候选词里面获取新的答案,从而节省了将答案重新输入模型再进行一次推理的时间。因此这种机制的优势在于,当一个候选词被验证为正确后,就无需再将其回输模型生成下一个答案,从而减少了推理的时间。
作为类比,可以把传统的自回归推理比作4×100米接力赛跑:在常规比赛中,四名运动员需按顺序逐个接棒完成全部赛程,这就好比自回归方案,需要逐字推理。而在SPACE的方案中,四名运动员是同步起跑的,当第一名运动员冲刺完100米到达终点的同时,其他运动员也到达了属于各自百米赛段的终点。但是第一名运动员到达终点后需要进行验证,若验证通过,第二名运动员的成绩即可确认,而后可以对第二名运动员进行验证,并依此类推。
若某名运动员未能通过验证,那他就需要返回至属于他的百米起跑线,重新起跑完成比赛。在最好的情况下,四个运动员每人都能通过验证,那么这个小组相当于只需要花常规比赛1/4的时间,就能完成比赛,从而达到加速效果;在最差的情况下,每个运动员都未能通过验证,那么这时候需要花的时间就跟常规比赛一样了。而能不能通过验证,主要取决于候选答案准不准确。
与此同时,在SPACE模型的推理过程中,我们也在输入中插入特殊的[MASK]标识,以此来引导大模型生成更新版的候选答案。在这种机制下,每一轮推理模型不仅验证了前一轮生成的候选词的准确性,也为接下来的推理提供了新的候选词。
这种设计旨在增强候选词的准确度,因为每当有新答案出现时,原有的候选词通过更新将变得更加精确。这个过程有如天气预报:我们每天都会对接下来一周的气候情况做出预测,并且随着时间的推移,对未来特定一天的天气预测准确度会逐渐提升。这是因为随着时间的推移,我们累积了更多的传感数据,这使得我们能够提供更为精确的天气预测。
传统的验证和修正方法,是上文提到的“投机解码”,即需要先训练出一个靠谱的小模型,再用大模型去验证,小模型的生成质量很大程度上影响了最终结果。
但SPACE提出了一种新的方案,不需要使用小模型,就能够达到生成和验证的目的,而且验证工作和生成工作可以同步进行。如此一来,推理的效率和准确率都能够得到大幅提升。
让我们再回到开头例子,当我们输入“大模型是什么?”,在SPACE推理模式下,大模型首先会同时生成“大模型是具有数千万参数的”这几个词,同时自动修正解码算法会立马对生成的多个词逐一进行验证,并且仅保留验证结果正确的词输出作为最终答案,从而实现在一次大模型前向推理的过程中生成多个词的效果,达到加速目的。
最后,让我们来看看SPACE的效果。
我们在一众开源大语言模型上进行了实验,实验涵盖了从60亿到700亿不同参数量的主流大语言模型。从下表中可以看到,SPACE在参数量更大的模型上,加速效果更明显。

此外,SPACE也能跟其他推理加速技术,例如continue batching, flash attention, KV cache, quantization等,一起结合使用,从而带来更快的推理速度。
为了验证这个观点,我们在一个主流推理框架TGI上实现了SPACE,实验证明在结合其他推理加速技术的情况下,SPACE带来的加速效果也是同样出众。

大模型走入千行百业,“推理”至关重要
训练和推理是大模型生命周期的两个核心阶段,训练是解决大模型“从无到有”的问题,而推理解决的是大模型如何应用到千行百业的问题。
如果将去年定义为大模型爆发的元年,那么今年就是大模型应用落地的元年,因此大模型的推理能力愈发受到重视。
云天励飞为加速大模型的应用做出了许多努力。在算力方面,去年公司推出大模型边缘推理芯片DeepEdge10.近期推出IPU-X6000加速卡,可应用于语言、视觉、多模态等各类大模型的推理加速。
在算法方面,云天励飞提出SPACE推理引擎,大幅提升大模型推理速度。在应用方面,云天励飞自研大模型云天天书已经在智慧政务、城市治理、智慧安防、智慧交通、智慧商业、智慧教育等多行业落地应用,探索打造行业标杆。
未来,云天励飞将继续努力,在大模型相关技术的研发和应用推广方面做出更大贡献。




